Concurrency From the Ground Up
Based on a talk presented at 360iDev 2018

As the title suggests, I want to look at concurrency from the ground up. Start from the basics: rather than queues and groups, pthreads and locks.
Why? GCD queues are complicated things, and I think understanding how the simpler, smaller pieces work can help.
Overall Goals
Why do we even care about concurrency? I think it’s an important tool in the toolbox to becoming better programmers and writing better programs.
And by writing better programs, I’m thinking of two things in particular:
- Programs that seem faster to the user
- Programs that are easy to understand for the programmer
Programs only need to seem faster to users, but they really do need to be easier to understand for programmers.
The How
Next, how are we going to do these things? With concurrency, we hope. We can look at three aspects in particular:
- Structuring our programs better. Programming as all about bringing structure to our ideas—that’s literally what code is. And concurrency as all about structures too, as we’ll discover.
- Thinking in terms of tasks. Once our programs are well-structured, we can get down to organizing on the code level. This means thinking about smaller tasks, threads of execution, and getting speed-ups thanks to multi-core hardware.
- Protecting resources. Finally, we need a mechanism for managing and protecting resources. We’re dealing with systems with limits—memory, CPU time, etc.—and we can look at locks as the concurrency primitive that helps us with resource management.
Concurrency & Structure
We use the word “concurrency” a lot when discussing things ranging from general performance, to doing more than one thing at once, to where to do UI work, to multi-core processors, and so on.
We have two words that we should try to understand better: concurrency and parallelism.
Here are some great quotes from a talk by Rob Pike:
“concurrency is the composition of independently executing processes”
So concurrency is about composition — composing things, these independently executing process things, into something else. It’s about organization and structure: how can we organize these little bits of work together into some cohesive whole?
Here’s the quote about parallelism:
“parallelism is the simultaneous execution of (possibly related) computations”
That seems simpler to me. It’s about simultaneous execution. Doing more than one thing at the same time.
To sum up:
“Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.”
Within this context, parallelism is outside the scope of things I need to do. I’m not the one doing lots of things at once. That’s the computer’s job, or the CPU, or the scheduler, or the operating system, or whatever.
Our job as programmers is the first part: making sure programs are structured in a way that lots of things at once are dealt with properly. We write programs with proper concurrency so the system can run things in parallel.
Decomposability
Another way to think about concurrency involves decomposability — having a large operation, and then breaking it up into pieces that are order-independent or partially ordered.
Maybe you’ve done this kind of refactoring before, where you have a lot of lines of code:

and you break them down into smaller functions:
Then you can replace the original code with a call to each function in turn.
A()
B()
C()
In the easiest case, this is literally a cut and paste job. When we think about decomposability, the easy case is if each of these new sub-functions is completely independent.
What do we mean by independent?
There’s a question of order: if we don’t care which of two tasks happens first, then maybe they’re independent.
There’s shared state: if two tasks have no shared state, then maybe they’re independent.
Mutable state throws a wrench into things: if a task mutates or generates some data, then we might need to start worrying about order.
If two units of work are order-independent then just throw them into the hopper and who cares when they happen?
If the units are order-dependent, then what? How do we ensure they’ll execute in the correct order?
Tasks & Threads
So we’ve broken our program down into smaller pieces. We’re thinking about tasks, and ordering.
And now we’re wondering, what mechanisms are there for us to handle these things? Once I’ve modeled my program into these small functions, how do I model the dependencies or the independence and parallelizeability between them?
We have threads and the pthread library available on Apple platforms to help us with this. The pthread library is a C library and is pretty low level; we probably deal with higher-level abstractions in our day-to-day lives but since we’re looking at concurrency from the ground up, let’s look at pthreads.
Live Coding Notes
The pthreads API needs functions with a certain signature:
func doWork(_ unused: UnsafeMutableRawPointer) -> UnsafeMutableRawPointer?
The function needs to take what would be a void * in C, and return one as well. In Swift that’s represented by UnsafeMutableRawPointer.
Our plan is to run two things in parallel, by setting up two tasks: one to show an activity indicator, and one to do the actual work.
Within the work thread, we can spin off additional threads to call our more specific functions.

The basics of pthreads:
- You create a thread and pass it a function pointer. The thread begins executing right away.
- You join a thread with
pthread_join, which is a blocking call that will wait for the thread to complete.
Live coding is hard to reproduce here; you should check out the video when it becomes available. 😆
You can browse a gist with the final code from this demo.
Locks & Resources
So we started with thinking about structure, and then breaking down code into functions.
If we use threads to model tasks, and we have tools like joining a thread to wait for it to complete, and we can cancel threads, then how do we model our concurrency needs around data and resources?
Locks are a super simple general-purpose thing for protecting resources. They’re like binary on/off switches that you use to ensure you’re not stepping on anyone else’s toes.
Locks are also cooperative — they’re like leaving a note somewhere saying “please don’t touch this until I say so” but the API only covers leaving that note and then removing it. It’s your responsibility to ensure the code takes heed of these notes.
Or, you can think of them like having a room full of people but you only want one person to speak at one time. So you have some kind of token, and you have to first acquire the token, speak, and then release or relinquish the token.
Live Coding Notes
You have the concept of acquiring a lock. That’s like leaving the note or acquiring the token.
Then you do whatever work you need to do.
Then you release, or unlock the lock.
That’s it!
Thinking about usage, you can imagine several ways to use locks:
- Locks as signals
- Locks as mutual exclusion
- Stringing together multiple locks to make a semaphore
- Using locks to sequence code together into a quasi-queue
You can browse a gist with the final code from this demo, where we looked at locks as signals and locks as mutexes.
Concluding Thoughts
Locks and threads are the concurrency primitives I think are most useful to understand how higher level concepts and APIs work.
But understanding and applying the concepts of concurrency means pulling together the specific needs of your application, structuring it correctly, and using the correct means to enable high performance.
There are a lot of APIs around locks, threads, queues, etc. available to us on the platform.
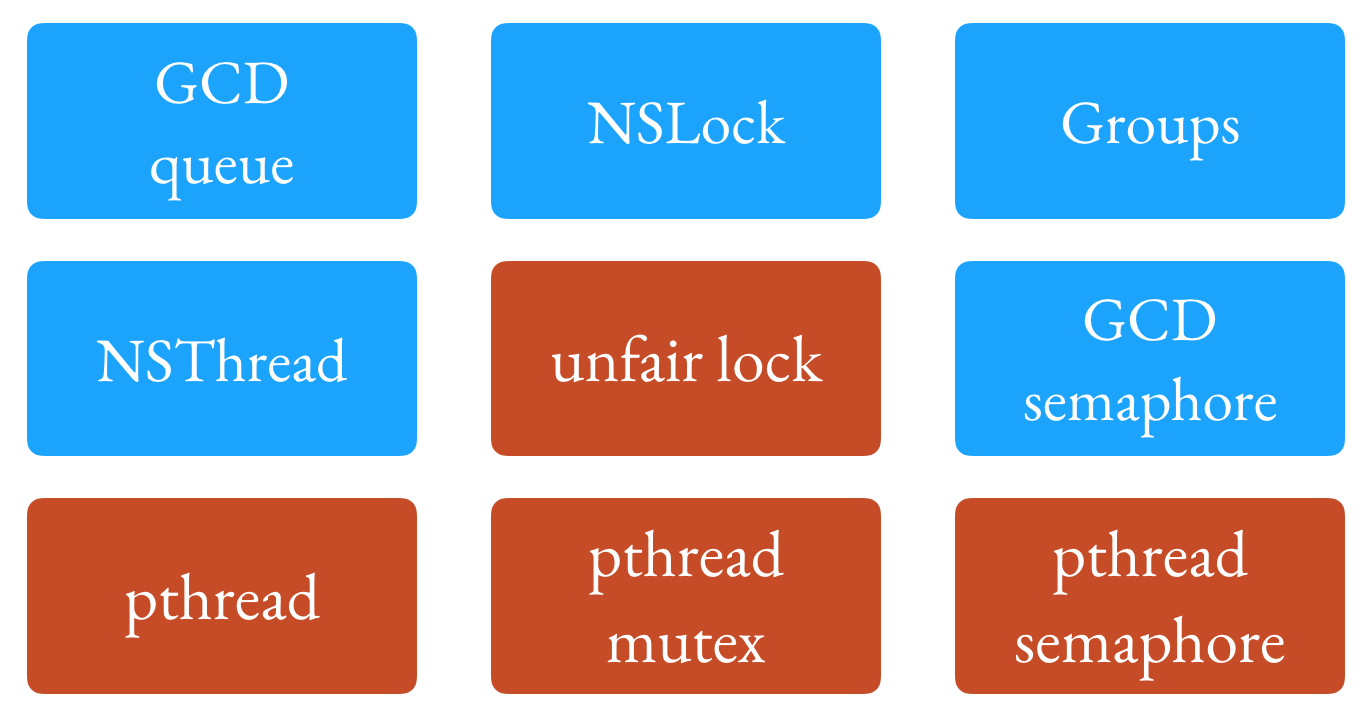
I hope this talk and article gives you some new things to research, and helps make you more thoughtful when thinking about structure and concurrency primitives when using those higher-level APIs. 😄